Introducing Gradio Clients
Watch
Introducing Gradio Clients
Watch This is the first in a two part series where we build a custom Multimodal Chatbot component. In part 1, we will modify the Gradio Chatbot component to display text and media files (video, audio, image) in the same message. In part 2, we will build a custom Textbox component that will be able to send multimodal messages (text and media files) to the chatbot.
You can follow along with the author of this post as he implements the chatbot component in the following YouTube video!
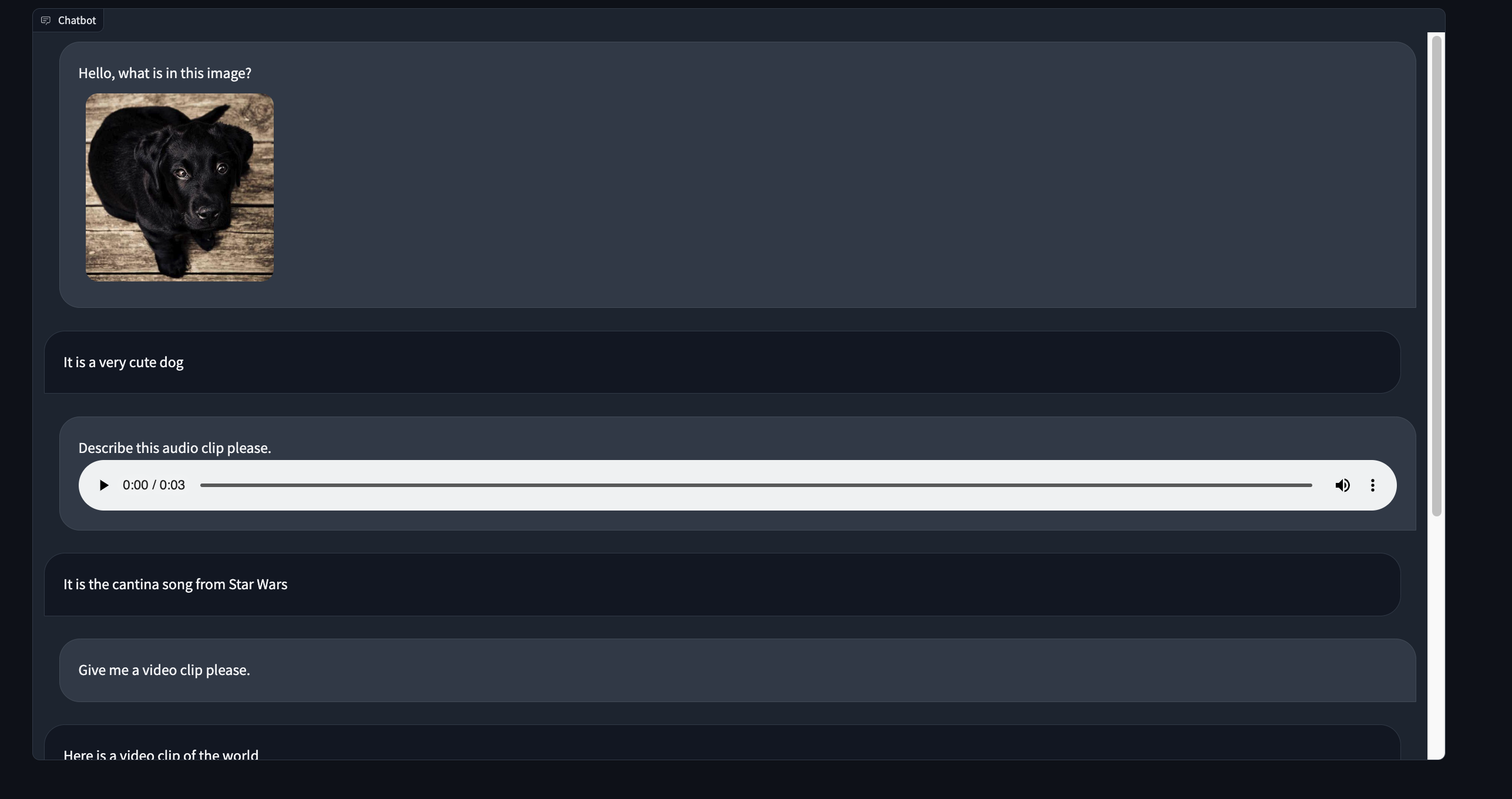
Here's a preview of what our multimodal chatbot component will look like:
%20Copyright%202022%20Fonticons,%20Inc.%20--%3e%3cpath%20d='M172.5%20131.1C228.1%2075.51%20320.5%2075.51%20376.1%20131.1C426.1%20181.1%20433.5%20260.8%20392.4%20318.3L391.3%20319.9C381%20334.2%20361%20337.6%20346.7%20327.3C332.3%20317%20328.9%20297%20339.2%20282.7L340.3%20281.1C363.2%20249%20359.6%20205.1%20331.7%20177.2C300.3%20145.8%20249.2%20145.8%20217.7%20177.2L105.5%20289.5C73.99%20320.1%2073.99%20372%20105.5%20403.5C133.3%20431.4%20177.3%20435%20209.3%20412.1L210.9%20410.1C225.3%20400.7%20245.3%20404%20255.5%20418.4C265.8%20432.8%20262.5%20452.8%20248.1%20463.1L246.5%20464.2C188.1%20505.3%20110.2%20498.7%2060.21%20448.8C3.741%20392.3%203.741%20300.7%2060.21%20244.3L172.5%20131.1zM467.5%20380C411%20436.5%20319.5%20436.5%20263%20380C213%20330%20206.5%20251.2%20247.6%20193.7L248.7%20192.1C258.1%20177.8%20278.1%20174.4%20293.3%20184.7C307.7%20194.1%20311.1%20214.1%20300.8%20229.3L299.7%20230.9C276.8%20262.1%20280.4%20306.9%20308.3%20334.8C339.7%20366.2%20390.8%20366.2%20422.3%20334.8L534.5%20222.5C566%20191%20566%20139.1%20534.5%20108.5C506.7%2080.63%20462.7%2076.99%20430.7%2099.9L429.1%20101C414.7%20111.3%20394.7%20107.1%20384.5%2093.58C374.2%2079.2%20377.5%2059.21%20391.9%2048.94L393.5%2047.82C451%206.731%20529.8%2013.25%20579.8%2063.24C636.3%20119.7%20636.3%20211.3%20579.8%20267.7L467.5%20380z'/%3e%3c/svg%3e)
For this demo we will be tweaking the existing Gradio Chatbot component to display text and media files in the same message.
Let's create a new custom component directory by templating off of the Chatbot component source code.
gradio cc create MultimodalChatbot --template ChatbotAnd we're ready to go!
Tip: Make sure to modify the `Author` key in the `pyproject.toml` file.
Open up the multimodalchatbot.py file in your favorite code editor and let's get started modifying the backend of our component.
The first thing we will do is create the data_model of our component.
The data_model is the data format that your python component will receive and send to the javascript client running the UI.
You can read more about the data_model in the backend guide.
For our component, each chatbot message will consist of two keys: a text key that displays the text message and an optional list of media files that can be displayed underneath the text.
Import the FileData and GradioModel classes from gradio.data_classes and modify the existing ChatbotData class to look like the following:
class FileMessage(GradioModel):
file: FileData
alt_text: Optional[str] = None
class MultimodalMessage(GradioModel):
text: Optional[str] = None
files: Optional[List[FileMessage]] = None
class ChatbotData(GradioRootModel):
root: List[Tuple[Optional[MultimodalMessage], Optional[MultimodalMessage]]]
class MultimodalChatbot(Component):
...
data_model = ChatbotDataTip: The `data_model`s are implemented using `Pydantic V2`. Read the documentation [here](https://docs.pydantic.dev/latest/).
We've done the hardest part already!
For the preprocess method, we will keep it simple and pass a list of MultimodalMessages to the python functions that use this component as input.
This will let users of our component access the chatbot data with .text and .files attributes.
This is a design choice that you can modify in your implementation!
We can return the list of messages with the root property of the ChatbotData like so:
def preprocess(
self,
payload: ChatbotData | None,
) -> List[MultimodalMessage] | None:
if payload is None:
return payload
return payload.rootTip: Learn about the reasoning behind the `preprocess` and `postprocess` methods in the [key concepts guide](./key-component-concepts)
In the postprocess method we will coerce each message returned by the python function to be a MultimodalMessage class.
We will also clean up any indentation in the text field so that it can be properly displayed as markdown in the frontend.
We can leave the postprocess method as is and modify the _postprocess_chat_messages
def _postprocess_chat_messages(
self, chat_message: MultimodalMessage | dict | None
) -> MultimodalMessage | None:
if chat_message is None:
return None
if isinstance(chat_message, dict):
chat_message = MultimodalMessage(**chat_message)
chat_message.text = inspect.cleandoc(chat_message.text or "")
for file_ in chat_message.files:
file_.file.mime_type = client_utils.get_mimetype(file_.file.path)
return chat_messageBefore we wrap up with the backend code, let's modify the example_value and example_payload method to return a valid dictionary representation of the ChatbotData:
def example_value(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]
def example_payload(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]Congrats - the backend is complete!
The frontend for the Chatbot component is divided into two parts - the Index.svelte file and the shared/Chatbot.svelte file.
The Index.svelte file applies some processing to the data received from the server and then delegates the rendering of the conversation to the shared/Chatbot.svelte file.
First we will modify the Index.svelte file to apply processing to the new data type the backend will return.
Let's begin by porting our custom types from our python data_model to typescript.
Open frontend/shared/utils.ts and add the following type definitions at the top of the file:
export type FileMessage = {
file: FileData;
alt_text?: string;
};
export type MultimodalMessage = {
text: string;
files?: FileMessage[];
}Now let's import them in Index.svelte and modify the type annotations for value and _value.
import type { FileMessage, MultimodalMessage } from "./shared/utils";
export let value: [
MultimodalMessage | null,
MultimodalMessage | null
][] = [];
let _value: [
MultimodalMessage | null,
MultimodalMessage | null
][];We need to normalize each message to make sure each file has a proper URL to fetch its contents from.
We also need to format any embedded file links in the text key.
Let's add a process_message utility function and apply it whenever the value changes.
function process_message(msg: MultimodalMessage | null): MultimodalMessage | null {
if (msg === null) {
return msg;
}
msg.text = redirect_src_url(msg.text);
msg.files = msg.files.map(normalize_messages);
return msg;
}
$: _value = value
? value.map(([user_msg, bot_msg]) => [
process_message(user_msg),
process_message(bot_msg)
])
: [];Let's begin similarly to the Index.svelte file and let's first modify the type annotations.
Import Mulimodal message at the top of the <script> section and use it to type the value and old_value variables.
import type { MultimodalMessage } from "./utils";
export let value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null;
let old_value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null = null;We also need to modify the handle_select and handle_like functions:
function handle_select(
i: number,
j: number,
message: MultimodalMessage | null
): void {
dispatch("select", {
index: [i, j],
value: message
});
}
function handle_like(
i: number,
j: number,
message: MultimodalMessage | null,
liked: boolean
): void {
dispatch("like", {
index: [i, j],
value: message,
liked: liked
});
}Now for the fun part, actually rendering the text and files in the same message!
You should see some code like the following that determines whether a file or a markdown message should be displayed depending on the type of the message:
{#if typeof message === "string"}
<Markdown
{message}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{:else if message !== null && message.file?.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
...We will modify this code to always display the text message and then loop through the files and display all of them that are present:
<Markdown
message={message.text}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{#each message.files as file, k}
{#if file !== null && file.file.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
src={file.file?.url}
title={file.alt_text}
on:play
on:pause
on:ended
/>
{:else if message !== null && file.file?.mime_type?.includes("video")}
<video
data-testid="chatbot-video"
controls
src={file.file?.url}
title={file.alt_text}
preload="auto"
on:play
on:pause
on:ended
>
<track kind="captions" />
</video>
{:else if message !== null && file.file?.mime_type?.includes("image")}
<img
data-testid="chatbot-image"
src={file.file?.url}
alt={file.alt_text}
/>
{:else if message !== null && file.file?.url !== null}
<a
data-testid="chatbot-file"
href={file.file?.url}
target="_blank"
download={window.__is_colab__
? null
: file.file?.orig_name || file.file?.path}
>
{file.file?.orig_name || file.file?.path}
</a>
{:else if pending_message && j === 1}
<Pending {layout} />
{/if}
{/each}We did it! 🎉
For this tutorial, let's keep the demo simple and just display a static conversation between a hypothetical user and a bot. This demo will show how both the user and the bot can send files. In part 2 of this tutorial series we will build a fully functional chatbot demo!
The demo code will look like the following:
import gradio as gr
from gradio_multimodalchatbot import MultimodalChatbot
from gradio.data_classes import FileData
user_msg1 = {"text": "Hello, what is in this image?",
"files": [{"file": FileData(path="https://gradio-builds.s3.amazonaws.com/diffusion_image/cute_dog.jpg")}]
}
bot_msg1 = {"text": "It is a very cute dog",
"files": []}
user_msg2 = {"text": "Describe this audio clip please.",
"files": [{"file": FileData(path="cantina.wav")}]}
bot_msg2 = {"text": "It is the cantina song from Star Wars",
"files": []}
user_msg3 = {"text": "Give me a video clip please.",
"files": []}
bot_msg3 = {"text": "Here is a video clip of the world",
"files": [{"file": FileData(path="world.mp4")},
{"file": FileData(path="cantina.wav")}]}
conversation = [[user_msg1, bot_msg1], [user_msg2, bot_msg2], [user_msg3, bot_msg3]]
with gr.Blocks() as demo:
MultimodalChatbot(value=conversation, height=800)
demo.launch()Tip: Change the filepaths so that they correspond to files on your machine. Also, if you are running in development mode, make sure the files are located in the top level of your custom component directory.
Let's build and deploy our demo with gradio cc build and gradio cc deploy!
You can check out our component deployed to HuggingFace Spaces and all of the source code is available here.
See you in the next installment of this series!